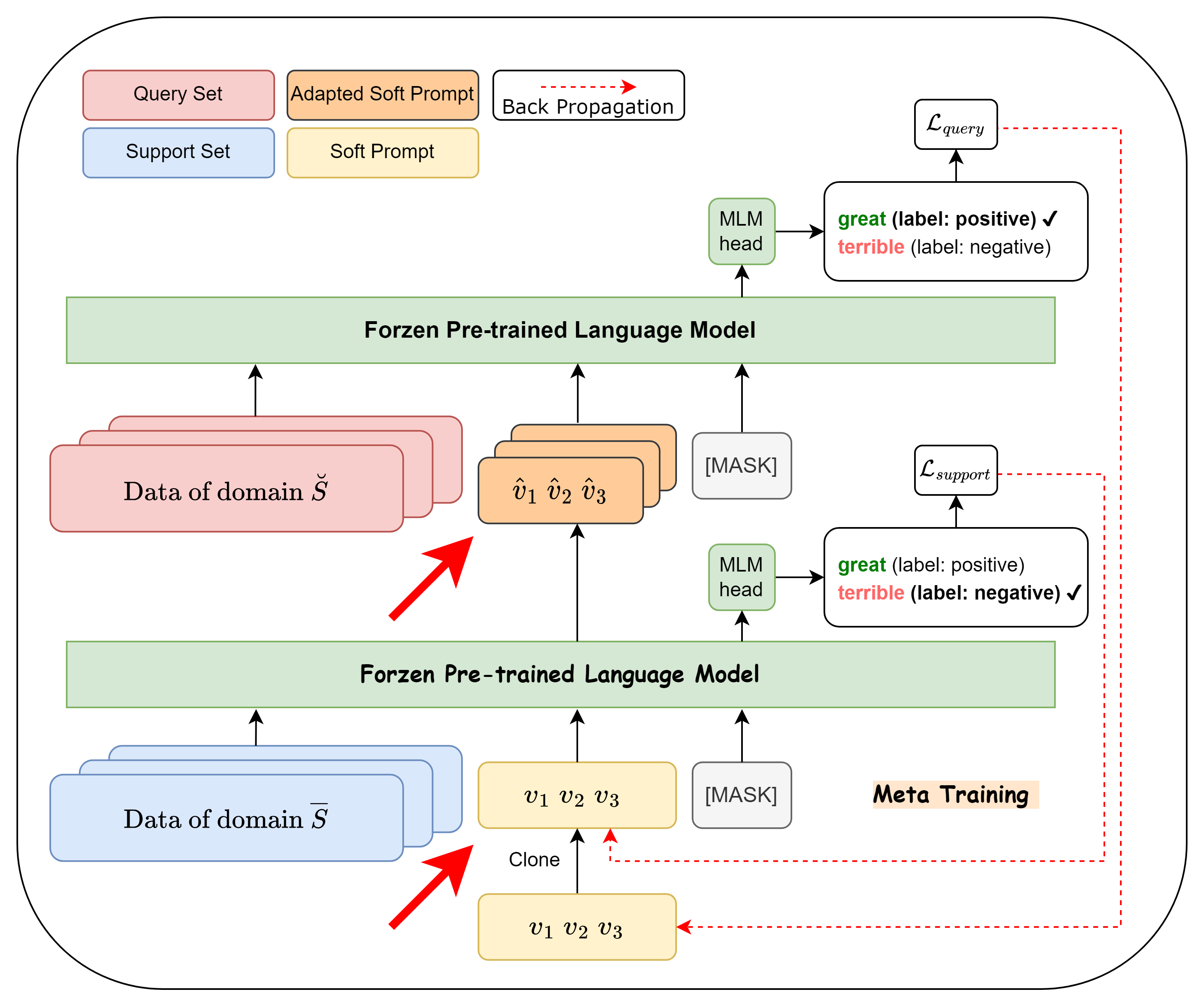
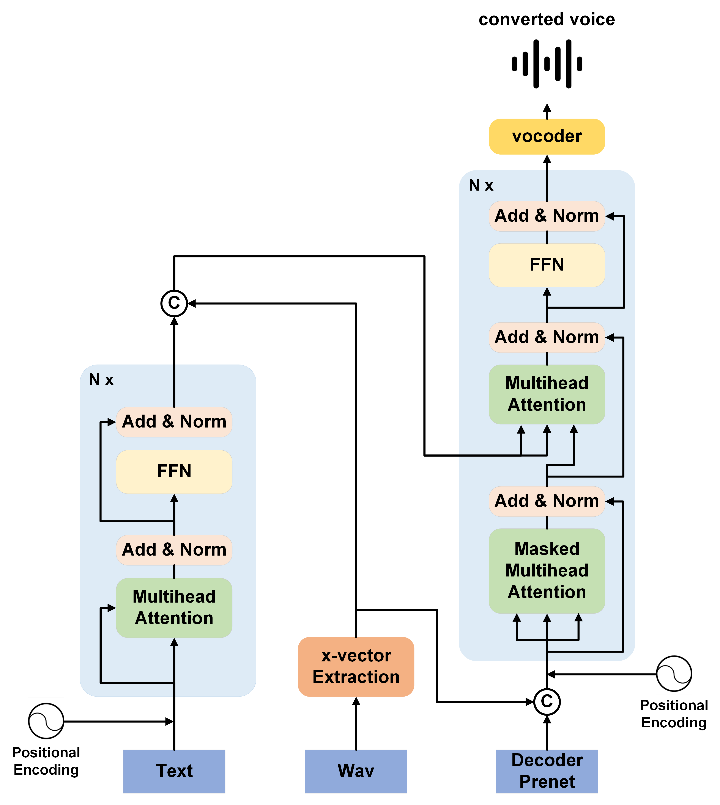
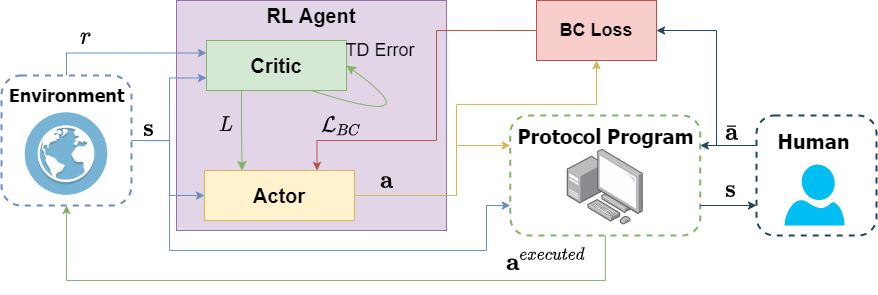
Introduction
本項目有以下幾個關鍵點:
1. 以「幫助緩解陽明交大學生所面臨的壓力問題」為主要目標,建立一個心理健康支持的聊天機器人。
2. 所構建之心理健康支持的對話模型雛型將整合基於規則(rule-based)的功能和基於學習(learning-based)的組件:將可以覆蓋所有用戶輸入,同時使其可控。
3. 將透過所設計的對話系統來收集用戶與系統的交互對話數據,並透過與心理諮商專業團隊合作以整理並標註對話數據。
4. 所設計的對話系統將語音作為輸入而不單是文字輸入,這與之前的許多作品不同:透過語音輸入,系統在不同的應用場景下將具有更高的靈活性;
5. 加入虛擬角色於使用者介面:增添與聊天機器人互動的真實感及趣味性,以提升用戶的願意參與度。
6. 可以處理雜訊和多樣輸入數據的穩健系統:通過使用大量對抗性示例訓練自然語言理解模塊(NLU),使對話管理器(dialog manager)於複雜情況下仍然可以提供正確的決策;
7. 將提出另一種關於解決自然句子生成中後驗坍塌(posterior collapse)問題的觀點:通過調整流模型(flow model)的規範,我們可以決定先驗和後驗之間的 KL 散度,以提供比以前的句子生成工作更大的靈活性;
8. 雙語對話系統:它可以透過 MultiWOZ 和 CrossWOZ 數據集中的數據在英文和中文間運作。
於本項目中,我們將收集相關的對話資料以做後續訓練模型之用。又資料集的品質乃是影響深度學習模型效能的重要因素之一,故我們參照先前於發表頂尖期刊論文Scientific Reports所發表的論文Sugariness prediction of Syzygium samarangense using convolutional learning of hyperspectral images,其利用深度學習演算法分析高光譜影像於果樹果實之光譜。
透過迴歸分析來輸出預測果樹果實之糖度值,在搜集過程中需要對採集過後的果實進行靜置、回溫的前處理。接著再將果實切片,使用高光譜儀器獲取果實的高光譜資料,其資料收集與處理之流程將被採納於之後的資料集建立程序中。
